
Building an AI search engine from scratch
![]()
PrAIvateSearch is an AI-powered, user-owned and local search engine
On 26th July 2024, OpenAI introduced a new prototype: SearchGPT, an applocation that would combine the power of their language models with resources from the web in an innovative approach to browsing the immense world of the Internet. SearchGPT was finally rolled out for Pro and Team users on 31st October 2024, as a “Search” extension of ChatGPT. OpenAI is just the tip of the iceberg: web browsing plug-ins and extensions for AI models have been added by numerous providers, and several agentic tools and workflows have been created to keep up with the growing popularity of web searching AIs (here is a non-exhaustive list).
The big problems with all these solutions is that the users do not own them: these services are provided to them by big companies (Google, OpenAI, Microsoft, Meta…), which can retain and postprocess user data, track them and employ them for various purposes, including marketing, training of new models and research. This is not illegal, as long as it is clearly stated in the privacy policies of the companies: examples of this data management policies can be found in OpenAI’s Privacy Policy, Google Gemini Apps Privacy Notice and Meta’s statement on Privacy and GenAI. Nevertheless, the fact that data, prompts and searches could be retained by Big Tech providers underlined the need of an AI-powered, user-owned search application, which we can now find as PrAIvateSearch, a local Gradio application with image- and text-based search capabilities.
The application structure and flow
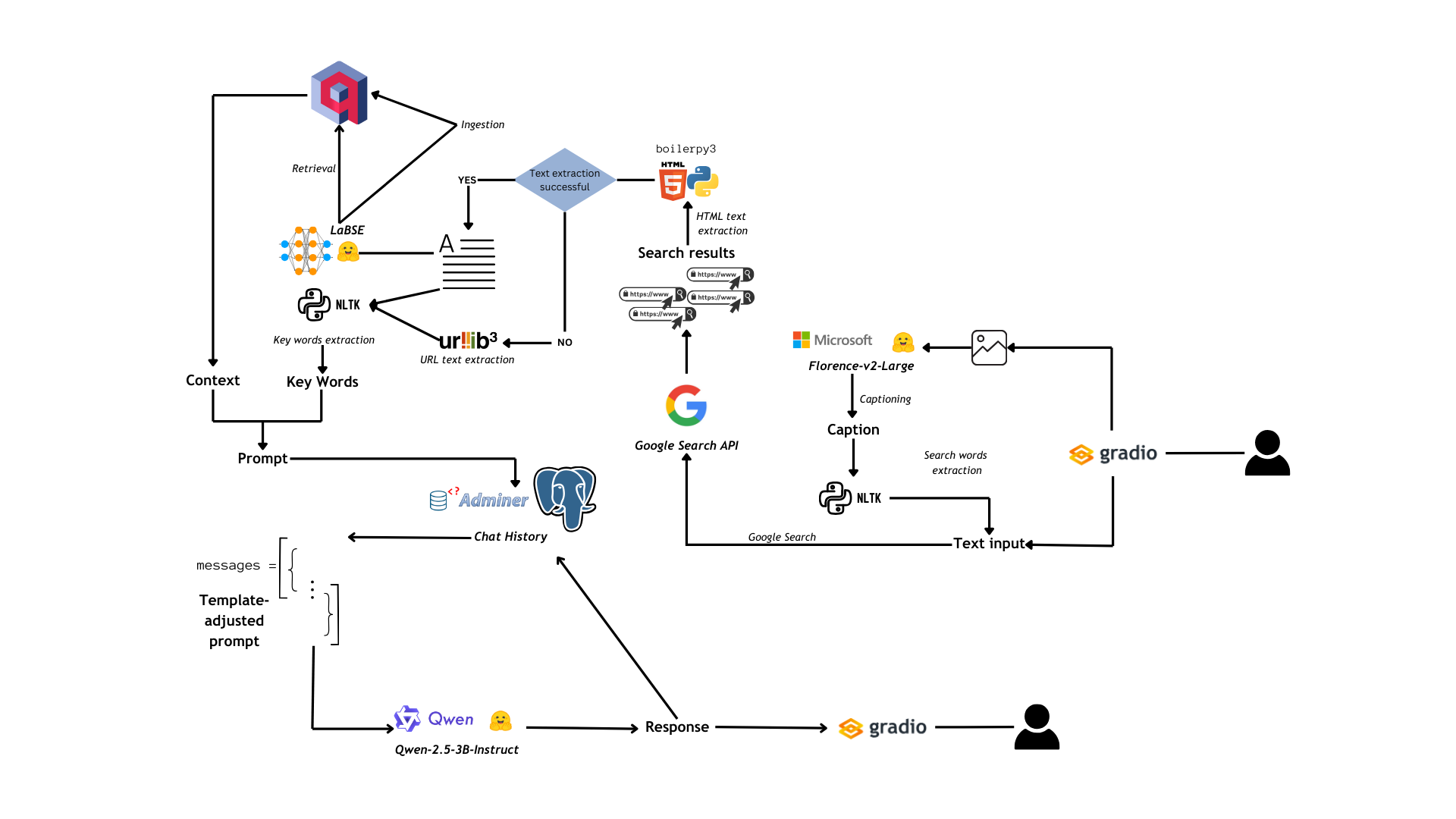
Fig. 1: Flowchart for PrAIvateSearch
The flow of the application is represented in Fig. 1 and it can be summarized in the following core steps:
- The user can provide, through the Gradio UI, two types of input to the app: image and text. If the input is text, it is directly used to search the web, whereas if the input is an image, this is captioned by Florence-2-large and from the caption are extracted search key words (with
rake_nltk, a python package based on the Natural Language ToolKit official package), that are then treated as text input. - Once we have our text input, this is used to search the web with the
googlesearch-pythonlibrary: this operation yields a list of URLs. - The text from the pages linked to the URLs is extracted using
boilerpy3and, whenboilerpy3fails, we employurllib3to extract the URL text directly. - The extracted text is then reduced to keywords, which are reported into a JSON-like structure that will be used to prompt the language model (which is instructed to interpret the JSON structure).
- In the meantime we vectorized the text obtained from the search with
LaBSEand we load it into a Qdrant database for future RAG application (if the user enables RAG functionalities). If the RAG functionalities are enabled, prior to data ingestion there is a retrieval step, which will then provide context to our language model based on content from previous searches. - The context, the keywords and the original query from the user get combined into a prompt, which is stored inside the Postgres database as part of the chat history. The chat history is then retrieved in a format which is compatible with the chat template that we set for our language model.
- It’s time for inference: Qwen-2.5-3B-Instruct (quantized in 4-bits through
bitsandbytesand loaded onto a GPU) is employed to produce an answer that takes into account search results and context, enriching it also with its knowledge. The assistant’s response is then added to the chat history - The response is displayed to the user through the UI.
The application is divided in two portions:
- A frontend one, rendered through the popular frontend framework Gradio
- A backend one, which is composed by two third-party database services (Postgres and Qdrant), a third-party Postgres-monitoring platform (Adminer) and the application itself (written in python)
Let’s dive deeper into the backend, while we will come to the frontend at the end.
Third-party services
There are three third-party services (Postgres, Qdrant and Adminer), which one could launch all together with the following compose file:
networks:
mynet:
driver: bridge
services:
db:
image: postgres
restart: always
ports:
- "5432:5432"
networks:
- mynet
environment:
POSTGRES_DB: $PG_DB
POSTGRES_USER: $PG_USER
POSTGRES_PASSWORD: $PG_PASSWORD
volumes:
- pgdata:/var/lib/postgresql/data
semantic_memory:
image: qdrant/qdrant
restart: always
ports:
- "6333:6333"
- "6334:6334"
networks:
- mynet
volumes:
- "./qdrant_storage:/qdrant/storage"
adminer:
image: adminer
restart: always
ports:
- "8080:8080"
networks:
- mynet
volumes:
pgdata:
This would work just by running:
# Add the detach option if you don't want to see the containers logs on your terminal
docker compose up [-d]
Let’s see what we can do with these services…
| Service | Port | Function | Python libraries |
|---|---|---|---|
| Postgres | 5432 | Chat history management (memory of the chatbot) | SQLAlchemy |
| Qdrant | 6333, 6334 | Semantic memory management (RAG functions for the chatbot) | qdrant_client |
| Adminer | 8080 | Monitor Postgres DB | / |
Table 1. Synthesis of the functions of the three services
1. Postgres
Postgres is employed for Chat History storage, and works basically as the memory of the chatbot.
To connect to the service, you should set your Postgrs user, password and database name in a .env file.
Whenever we start our application, we create two tables: conversations (which stores the conversation IDs, the user IDs and the time of start) and messages, which store the messages for the current conversation.
We created a client with SQLAlchemy to interact with Postgres:
# https://github.com/AstraBert/PrAIvateSearch/tree/main/lib/scripts/memory.py
from sqlalchemy import MetaData, create_engine, text
from sqlalchemy.orm import sessionmaker
import warnings
class ErrorOccuredWarning(Warning):
"""An error occured but it was handled by try...except"""
class PGClient:
def __init__(self, connection_string: str):
"""
Initialize a Client instance.
Args:
connection_string (str): A string representing the database connection information.
Returns:
None
"""
self.engine = create_engine(connection_string)
self.meta = MetaData(schema="public")
self.Session = sessionmaker(self.engine)
with self.Session() as sess:
with sess.begin():
sess.execute(text("create schema if not exists public;"))
def execute_query(self, query):
try:
with self.Session() as sess:
with sess.begin():
res = sess.execute(text(query))
return res
except Exception as e:
warnings.warn(f"An error occurred: {e}", ErrorOccuredWarning)
return None
def disconnect(self) -> None:
"""
Disconnect the client from the database.
Returns:
None
"""
self.engine.dispose()
return
And then we built the actual conversation history class, which allows us to add messages, specifying the role (user, system or assistant) and the content of the message, and to retrieve the message history in a way which is compatible with the chat-template established for our language model:
# https://github.com/AstraBert/PrAIvateSearch/tree/main/lib/scripts/memory.py
class ConversationHistory:
def __init__(self, client: PGClient, user_id: int):
self.client = client
self.user_id = user_id
self.client.execute_query("""DROP TABLE IF EXISTS conversations;""")
self.client.execute_query("""DROP TABLE IF EXISTS messages;""")
self.client.execute_query("""CREATE TABLE conversations (
id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);""")
self.client.execute_query("""CREATE TABLE messages (
id SERIAL PRIMARY KEY,
conversation_id INTEGER REFERENCES conversations(id),
role VARCHAR(10) NOT NULL,
content TEXT NOT NULL,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);""")
conv_id = self.client.execute_query(f"INSERT INTO conversations (user_id) VALUES ({self.user_id}) RETURNING id")
conversation_id = conv_id.fetchone()[0]
self.conversation_id = conversation_id
def add_message(self, role, content):
content = content.replace("'","''")
self.client.execute_query(f"INSERT INTO messages (conversation_id, role, content) VALUES ({self.conversation_id}, '{role}', '{content}')")
def get_conversation_history(self):
res = self.client.execute_query(f"SELECT role, content FROM messages WHERE conversation_id = {self.conversation_id} ORDER BY timestamp ASC")
messages = res.fetchall()
return [{"role": role, "content": content} for role, content in messages]
2. Qdrant
Qdrant allows us to enrich the prompts that are presented to our language model with a context coming from previous searches. At every search, the text from the articles that the search produced gets chunked, vectorized by LaBSE (a text embedding model) and uploaded to a Qdrant collection. If the RAG functionalities are enabled by the user, then LaBSE would vectorize query and the search results, performing vector search inside the collection and retrieving a context that will be given to the language model.
Let’s see how we implemented this in our application:
- We first defined an
upload_to_qdrantfunction that employslangchaintext splitting functionalities, LaBSE embeddings throughsentence-transformersandqdrant_clientfor data points upsertion.
# https://github.com/AstraBert/PrAIvateSearch/tree/main/lib/scripts/websearching.py
from langchain.text_splitter import CharacterTextSplitter
from qdrant_client import QdrantClient, models
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("sentence-transformers/LaBSE")
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
collection_name = f"cute_kitty_{r.randint(1,10000)}"
qdrant_client = QdrantClient("http://localhost:6333")
qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(
size=encoder.get_sentence_embedding_dimension(), # Vector size is defined by used model
distance=models.Distance.COSINE,
),
)
def upload_to_qdrant(client: QdrantClient, collection_name: str, encoder: SentenceTransformer, text: str):
try:
chunks = splitter.split_text(text)
docs = []
for chunk in chunks:
docs.append({"text": chunk})
client.upload_points(
collection_name=collection_name,
points=[
models.PointStruct(
id=idx,
vector=encoder.encode(doc["text"]).tolist(),
payload=doc,
)
for idx, doc in enumerate(docs)
],
)
return True
except Exception as e:
return False
- We then proceeded to create class to perform dense retrieval:
# https://github.com/AstraBert/PrAIvateSearch/tree/main/lib/scripts/rag.py
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
class NeuralSearcher:
# Convert text query into vector
vector = self.model.encode(text).tolist()
# Use `vector` for search for closest vectors in the collection
search_result = self.qdrant_client.search(
collection_name=self.collection_name,
query_vector=vector,
query_filter=None, # If you don't want any filters for now
limit=limit,
)
payloads = [hit.payload for hit in search_result]
return payloads
3. Adminer
Adminer is a tool to monitor your PostgreSQL databases. You can access the service by setting the service type as PostgreSQL, and then you can proceed to login with the credentials you set in you .env file (find an example here).
You will be able to check the conversations and the messages table.
Other backend components
1. Image captioning and search word extraction
As we said, PrAIvateSearch supports image-based inputs for search purposes. This is possible because, internally, images are converted to text inputs thanks to a SOTA image captioning model, Florence-2-large by Microsoft. The image caption, nevertheless, generally contains information that are misleading for the search, for example: “This image shows” Or “In this image you can see”. In this case we perform key-word extraction with RAKE (Rapid Algorithm for Keyword Extraction) implementation by NLTK, and we proceed to exclude all the words and expressions that contain “image*”.
We do this with the following script:
# https://github.com/AstraBert/PrAIvateSearch/tree/main/lib/script/image_gen.py
import warnings
warnings.filterwarnings("ignore")
import einops
import timm
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
from rake_nltk import Metric, Rake
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-large", torch_dtype=torch_dtype, trust_remote_code=True).to(device)
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True)
task_prompt = "<DETAILED_CAPTION>"
raker = Rake(include_repeated_phrases=False, ranking_metric=Metric.WORD_DEGREE)
def extract_keywords_from_caption(caption: str) -> str:
raker.extract_keywords_from_text(caption)
keywords = raker.get_ranked_phrases()[:5]
fnl = []
for keyword in keywords:
if "image" in keyword:
continue
else:
fnl.append(keyword)
return " ".join(fnl)
def caption_image(image):
global task_prompt
prompt = task_prompt
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device, torch_dtype)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
num_beams=3
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task=task_prompt, image_size=(image.width, image.height))
caption = parsed_answer["<DETAILED_CAPTION>"]
search_words = extract_keywords_from_caption(caption)
return search_words
As you can see, also Florence is loaded on GPU for faster inference.
The resulting key words are treated as text input and sent to Google Search as query.
2. Web Search, RAG and prompt building
We perform a search through Google Search python package (the user can set the maximum number of retrieved results from 1 to 10): this yields a list of URLs, whose content we then proceed to read with boilerpy3 (or, in case of failure, we extract text directly from the URL with urllib3). Each text thus obtained is then mapped into a dictionary to its 20 (max) most important key words (extracted with RAKE), and the dictionary is then dumped into a JSON-like string, reported under the “KEYWORDS” section in the final prompt. If no keywords are yielded from the search, this is explicitly set in the JSON structure.
If RAG is enabled, the three most important contexts are retrieved and packed together to form the prompt under the “CONTEXT” section of it. At the beginning to the prompt, in the section “QUERY”, we report the original text query by the user/extracted query from the image input. Before returning the prompt, nevertheless, we chunk the content we retrieved from the search, vectorize it and send it to our Qdrant collection.
Our websearching.py now will be complete and will look like this:
# https://github.com/AstraBert/PrAIvateSearch/tree/main/lib/scripts/websearching.py
import warnings
warnings.filterwarnings("ignore")
from googlesearch import search
from rake_nltk import Rake
from boilerpy3 import extractors
import json
from langchain.text_splitter import CharacterTextSplitter
from qdrant_client import QdrantClient, models
from sentence_transformers import SentenceTransformer
from rag import NeuralSearcher
import random as r
from datetime import datetime
from urllib.parse import urlparse
encoder = SentenceTransformer("sentence-transformers/LaBSE")
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
extractor = extractors.ArticleExtractor()
collection_name = f"cute_kitty_{r.randint(1,10000)}"
qdrant_client = QdrantClient("http://localhost:6333")
searcher = NeuralSearcher(collection_name, qdrant_client, encoder)
r = Rake()
qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(
size=encoder.get_sentence_embedding_dimension(), # Vector size is defined by used model
distance=models.Distance.COSINE,
),
)
def extract_corpus(url):
# Parse the URL to get its components
parsed_url = urlparse(url)
# Extract the domain name without subdomains or TLD
domain = parsed_url.netloc.split('.')
# Return the main word (corpus)
if len(domain) > 2: # Handle subdomains
return domain[-2]
return domain[0]
def upload_to_qdrant(client: QdrantClient, collection_name: str, encoder: SentenceTransformer, text: str):
try:
chunks = splitter.split_text(text)
docs = []
for chunk in chunks:
docs.append({"text": chunk})
client.upload_points(
collection_name=collection_name,
points=[
models.PointStruct(
id=idx,
vector=encoder.encode(doc["text"]).tolist(),
payload=doc,
)
for idx, doc in enumerate(docs)
],
)
return True
except Exception as e:
return False
def date_for_debug():
date = datetime.now()
s = f"{date.year}-{date.month}-{date.day} {date.hour}:{date.minute}:{date.second}"
return s
# Function to perform web search
def web_search(query, num_results=5, enable_rag=False, debug = True):
global qdrant_client, encoder, collection_name
search_results = []
for url in search(query, num_results=num_results):
search_results.append(url)
urls = list(set(search_results))
jsonlike = {}
finalcont = ""
if len(urls) > 0:
for url in urls:
try:
content = extractor.get_content_from_url(url)
r.extract_keywords_from_text(content)
keywords = r.get_ranked_phrases()[:20]
jsonlike.update({url: {"keywords": keywords}})
finalcont+=content+"\n\n"
except Exception as e:
if debug:
print(f"[{date_for_debug()}] WARNING! {e}")
content = extract_corpus(url) + " " + " ".join(url.split("/")[3:])
r.extract_keywords_from_text(content)
keywords = r.get_ranked_phrases()[:20]
jsonlike.update({url: {"keywords": keywords}})
finalcont += content
continue
else:
jsonlike = {"keywords": "THE SEARCH DID NOT PRODUCE MEANINGFUL RESULTS (base the answer on the context, if given)"}
context = ""
if enable_rag:
res = searcher.search(finalcont, 3)
for i in range(len(res)):
context += res[i]["text"]+"\n\n"+"---------------"+"\n\n"
truth = upload_to_qdrant(qdrant_client, collection_name, encoder, finalcont)
jsonstr = json.dumps(jsonlike)
if truth:
if context:
return "QUERY:\n\n"+query+"\n\nKEYWORDS:\n\n"+jsonstr+"\n\nCONTEXT:\n\n"+context, f"[{date_for_debug()}] SUCCESS! Semantic memory successfully updated!"
else:
return "QUERY:\n\n"+query+"\n\nKEYWORDS:\n\n"+jsonstr, f"[{date_for_debug()}] SUCCESS! Semantic memory successfully updated!"
if context:
return "QUERY:\n\n"+query+"\n\nKEYWORDS:\n\n"+jsonstr+"\n\nCONTEXT:\n\n"+context, f"[{date_for_debug()}] WARNING! Something went wrong while updating semantic memory"
return "QUERY:\n\n"+query+"\n\nKEYWORDS:\n\n"+jsonstr, f"[{date_for_debug()}] WARNING! Something went wrong while updating semantic memory"
Be careful with RAG functionalities! YES, Qwen-2.5-3B-Instruct is a relatively small model that, quantized, takes up approx. 2GB of the GPU vRAM, BUT if you provide it with a context that is too long it can take hours to process your prompt and generate a response (especially if your hardware is not the most powerful)
3. Verbose debugging information
You may have noticed that we included several debug variables in our functions. If the debugging option is true (and by default it is), you can view several processes, including start/end of query processing, semantic memory updates and chat history logs, directly on your terminal. This is particularly useful when it comes to understanding what could have gone wrong if you have some problems and evaluating the app performance.
4. Text inference
Text inference is the very last part of the backend, and involves Qwen generating a response to the user’s prompt.
As we said, we first created a chat template, using trl and transformers, the same awesome library by HuggingFace that manages all the AI models loading. This chat template is then basically copied by the structure of how the chat history is stored in the Postgres DB, and in the way it is retrieved by the get_chat_history function.
The entire list of messages is used to prompt Qwen, which then generates an answer based on that. The assistant’s answer is then uploaded to the Postgres database. This is the code implementation:
# https://github.com/AstraBert/PrAIvateSearch/blob/main/lib/scripts/text_inference.py
import warnings
warnings.filterwarnings("ignore")
import accelerate
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from dotenv import load_dotenv
from memory import ConversationHistory, PGClient
import os
import random as r
from trl import setup_chat_format
from websearching import date_for_debug
load_dotenv()
model_name = "Qwen/Qwen2.5-3B-Instruct"
quantization_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type= "nf4"
)
quantized_model = AutoModelForCausalLM.from_pretrained(model_name, device_map="cuda:0", torch_dtype=torch.bfloat16,quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.chat_template = None
quantized_model, tokenizer = setup_chat_format(model=quantized_model, tokenizer=tokenizer)
pg_db = os.getenv("PG_DB")
pg_user = os.getenv("PG_USER")
pg_psw = os.getenv("PG_PASSWORD")
pg_conn_str = f"postgresql://{pg_user}:{pg_psw}@localhost:5432/{pg_db}"
pg_client = PGClient(pg_conn_str)
usr_id = r.randint(1,10000)
convo_hist = ConversationHistory(pg_client, usr_id)
convo_hist.add_message(role="system", content="You are a web searching assistant: your task is to create a human-readable content based on a JSON representation of the keywords of several websites related to the search that the user performed and on the context that you are provided with")
def pipe(prompt: str, temperature: float, top_p: float, max_new_tokens: int, repetition_penalty: float):
tokenized_chat = tokenizer.apply_chat_template(prompt, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = quantized_model.generate(tokenized_chat, max_new_tokens=max_new_tokens, temperature=temperature, top_p=top_p, repetition_penalty=repetition_penalty)
results = tokenizer.decode(outputs[0])
return results
def text_inference(message, debug):
convo_hist.add_message(role="user", content=message)
prompt = convo_hist.get_conversation_history()
if debug:
print(f"[{date_for_debug()}] CONVERSATIONAL HISTORY")
print(prompt)
res = pipe(
prompt,
temperature=0.1,
top_p=1,
max_new_tokens=512,
repetition_penalty=1.2
)
ret = res.split("<|im_start|>assistant\n")[1]
convo_hist.add_message(role="assistant", content=ret)
return ret
Frontend and UI
As we said, the frontend is managed through Gradio, a popular UI-building framework for python developers. The interface is built with a text box for text-based input, an image uploading widget and a slider to select the number of Google Search results. We also have two checkbox options to enable/disable RAG and debugging functionalities.
The output is instead wrapped inside a Markdown-rendering text area.
Here is the code for our app.py file:
# https://github.com/AstraBert/PrAIvateSearch/blob/main/lib/scripts/app.py
import warnings
warnings.filterwarnings("ignore")
import gradio as gr
from text_inference import text_inference
from image_gen import caption_image
from PIL import Image
from websearching import web_search, date_for_debug
def reply(text_input, image_input=None, max_results=5, enable_rag=False, debug = True):
if debug:
print(f"[{date_for_debug()}] Started query processing...")
if image_input is None:
prompt, qdrant_success = web_search(text_input, max_results, enable_rag, debug)
if debug:
print(qdrant_success)
results = text_inference(prompt, debug)
results = results.replace("<|im_end|>","")
if debug:
print(f"[{date_for_debug()}] Finished query processing!")
return results
else:
if text_input:
img = Image.fromarray(image_input)
caption = caption_image(img)
full_query = caption +"\n\n"+text_input
prompt, qdrant_success = web_search(full_query, max_results, enable_rag)
if debug:
print(qdrant_success)
results = text_inference(prompt, debug)
results = results.replace("<|im_end|>","")
if debug:
print(f"[{date_for_debug()}] Finished query processing!")
return results
else:
img = Image.fromarray(image_input)
caption = caption_image(img)
prompt, qdrant_success = web_search(caption, max_results, enable_rag)
if debug:
print(qdrant_success)
results = text_inference(prompt, debug)
results = results.replace("<|im_end|>","")
if debug:
print(f"[{date_for_debug()}] Finished query processing!")
return results
iface = gr.Interface(fn=reply, inputs=[gr.Textbox(value="",label="Search Query"), gr.Image(value=None, label="Image Search Query"), gr.Slider(1,10,value=5,label="Maximum Number of Search Results", step=1), gr.Checkbox(value=False, label="Enable RAG"), gr.Checkbox(value=True, label="Debug")], outputs=[gr.Markdown(value="Your output will be generated here", label="Search Results")], title="PrAIvateSearch")
iface.launch(server_name="0.0.0.0", server_port=7860)
Getting the app up and running
To get the app up and running, you first of all should install all the necessary dependencies:
# Get the requirements file
wget https://raw.githubusercontent.com/AstraBert/PrAIvateSearch/main/requirements.txt
# Create a virtual environment
python3 -m venv virtualenv
# Activate the virtual environment
source virtualenv/bin/activate
# Install dependencies
python3 -m pip install -r requirements.txt
Secondly, you should initialize the third-party services:
# Get the requirements file
wget https://raw.githubusercontent.com/AstraBert/PrAIvateSearch/main/compose.yaml
# Run the third-party servicess
docker compose up
Last but not least, run the application and head over to http://localhost:7860 when the loading is complete:
# Clone the repository
wget https://github.com/AstraBert/PrAIvateSearch.git
# Go inside the directory
cd PrAIvateSearch
# Run the app
python3 lib/scripts/app.py
You will now be able to play around with it as much as you want!
Conclusion
The aim behind PrAIvateSearch is to provide an open-source, private and data-safe alternative to Big Tech solutions. The application is still a beta, so, although its workflow may seem solid, there may still be hiccups, untackled errors and imprecisions. If you want to contribute to the project, report issues and help developing the OSS AI community and environment, feel free to do so on GitHub and to help it with funding.
Thanks!🤗