
Repetita iuvant: how to improve AI code generation
Introduction: Codium-AI experiment
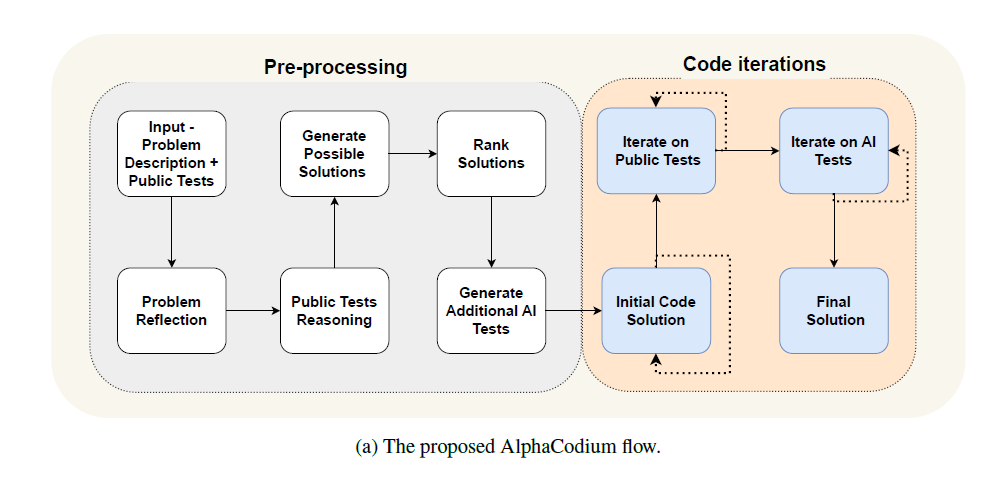
This image, taken from Codium-AI’s January paper (Ridnik et al., 2024) in which they introduced AlphaCodium, displays what most likely is the next-future of AI-centered code generation.
Understanding this kind of workflow is then critical not only to developers, but also to non-technical people who occasionally would need to do some coding: let’s break it down, as usual in a plain and simple way, so that (almost) everyone can understand!
0. The starting point
0a. The dataset
AlphaCodium (that’s the name of the workflow in the image) was conceived as a way to tackle complex programming, contained in CodeContest, a competitive coding dataset that encompasses a large number of problems representing all sort of reasoning challenges for LLMs.
The two great advantages of using CodeContest dataset are:
- Presence of public tests (sets of input values and results that developers can access during the competition too see how their code performs) and numerous private tests (accessible only to the evaluators). This is really important because private tests avoid “overfitting” issues, which means that they prevent LLMs from producing some code perfectly tailored on public tests to pass them, when in reality it doesn’t really work in a generalized way. To sum this up, private tests avoid false positives
- CodeContest problems are not just difficult to solve: they contain small details, subtleties that LLMs, caught up in their strive to generalize the question they are presented, do not usually notice.
0b. Competitor models
Other models or flows addressed the challenge of smoothing complex reasoning in code generation; the two explicitly mentioned in Codium-AI’s paper are:
- AlphaCode by Google Deepmind was finetuned specifically on CodeContest: it produces millions of solutions, of which progressively smaller portions get selected based on how well they fit the problem representation. In the end, only 1-10 solutions are retained. Even though it had impressive results at the time, the computational burden makes this an unsuitable solution for everyday users.
- CodeChain by Le et al. (2023) had the aim to enhance modular code generation capacity, to make the outputs more similar to the ones skilled developers would produce. This is achieved through a chain of self-revisions, guided by previously produced snippets.
Spoiler: neither of them proves as good as AlphaCodium on the reported benchmarks in the paper.
1. The flow
1a. Natural language reasoning
As you can see in the image at the beginning of this article, AlphaCodium’s workflow is divided in two portions. The first one encompasses thought processes in which mostly natural language is involved, hence we could call it the Natural Language Reasoning (NLR) phase.
- We start with a prompt that contains both the problem and the public tests
- We proceed to ask the LLM to “reason out loud” on the problem
- The same reasoning procedure goes for the public tests
- After having produced some thoughts on the problem, the model outputs a first batch of potential solutions
- The LLM is then asked to rank these solutions according to their suitability for problem and public tests
- To further test the model’s understanding of the starting problem, we ask it to produce other tests, which we will be using to evaluate the code solutions performances.
1b. Coding test iterations
The second portion includes actual code execution and evaluation with public and AI-generated tests:
- We make sure that the initial code solution works without bugs: if not, we regenerate it until we either reach a maximum iteration limit or produce an apparently zero-bug solution
- Public tests are then taken over by the model’s code: we search for the solution that maximizes passes over fails over several iteration rounds; this solution is passed over to the AI tests
- The last step is to test the code against AI-generated input/outputs: the solution that best fits them is returned as the final one, and will be evaluated with private tests.
This second portion may leave us with some questions, such as: what if the model did not understand the problem and produced wrong tests? How do we prevent the degeneration of code if there are corrupted AI-generated tests?
These questions will be addressed in the next section.
2. Performance-enhancing solutions
2a. Generation-oriented workarounds
The first target that Codium-AI scientists worked on was the generation of natural language reasoning and the production of coding solutions:
- They made the model reason in a concise but effective way, explicitly asking it to structure its thoughts in bullet points: this strategy proved to improve the quality of the output when the LLM was asked to reason about issues
- AI was asked to generate outputs in YAML format, which is easier to generate and parse than JSON format, enabling also to eliminate all the hassle of prompt engineering and allowing to solve advanced problems
- Direct questions and one-block solutions are postponed, to the advantage of reasoning and exploration. Putting “pressure” on the model to find the best solution often leads to hallucinations and make the LLM go down the rabbit hole without coming back.
2b. Code-oriented workarounds
The questions at the end of section 1 represent important issues for AlphaCodium, which can significantly deteriorate its performance - but the authors of the paper found solutions to them:
- Soft decisions and self-validation to tackle wrong AI-generated tests: instead of asking the model to evaluate its tests with a “Yes”/”No”, trenchant answer, we make it reason about the correctness of its tests, code and outputs altogether. This leads to “soft decisions”, which make the model adjust its tests.
- Anchor tests avoid code degeneration: imagine that AI tests are wrong even after revisions, then the code solution might be right but still not pass the LLM-generated tests. In this sense, the model would go on and modify its code, making it inevitably unfit for the real solution: to avoid this deterioration, AlphaCodium identifies “anchor tests”, i.e. public tests that the code passed and that it should pass also after AI-tests iterations, to be retained as a solution.
3. Results
When LLMs were directly asked to generate code from the problem (direct prompt approach), AlphaCodium-enhanced open- (DeepSeek-33B) and closed-source (GPT3.5 and GPT4) models outperformed their base counterpart, with a 2.3x improvements in GPT4 performance (from 19 to 44%) as an highlight.
The comparison with AlphaCode and CodeChain was instead made with a pass@k metric (which means the percentage of test passing with k generated solution): AlphaCodium’s pass@5 with both GPT3.5 and GPT4 was higher than AlphaCode’s pass@1k@10 (1000 starting solutions and 10 selected final ones) and pass@10k@10, especially in the validation phase. CodeChain’s pass@5 with GPT3.5 was also lower than AlphaCodium’s results.
In general, this self-corrective and self-reasoning approach seems to yield better performances than the models by themselves or other complex workflows.
Conclusion: what are we gonna do with all this future?
AlphaCodium’s workflow represent a reliable and solid way to enhance models performances in code generation, exploiting a powerful combination of NLR and corrective iterations.
This flow is simple to understand, involves 4 orders of magnitude less LLM calls than AlphaCode and can provide a fast and trustable solution even to non-professional coders.
The question that remains is: what are we gonna do with all this future? Are we going to invest in more and more data and training to build better coding models? Will we rely on fine-tuning or monosemanticy properties of LLMs to enhance their performances on certain downstream tasks? Or are we going to develop better and better workflows to improve base, non-finetuned models?
There’s no simple answer: we’ll see what the future will bring to us (or, maybe, what we will bring to the future).
References
- Ridnik T, Kredo D, Friedman I and Codium AI Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering. ArXiv (2024). https://doi.org/10.48550/arXiv.2401.08500
- GitHub repository