
Transformers architecture for everyone
Transformers revolution
Ever wondered what does GPT stand for? In case you did and you didn’t have time or weren’t willing to find an answer, here it is: Generative Pretrained Transfomer. Now: for Generative and Pretrained, we can easily think of an explanation, whereas “transformer” is not something we deal with in our everyday life (at least not that we are aware of). Let’s dive a little bit further in the subject, then, by exploring in plain and simple terms what are transformers and what could we do with them.
A new technique
Long before transformers were actually implemented, neural networks such as Recurrent or Long Short Term Memory ones were tested on tasks such as Machine Transduction (performing automated transformation on an input to generate a new output). There were, nevertheless, two big problems:
- Vanishing gradient: the learning of the neural networks was not as stable as expected and large inputs (such as long sentences for Natural Language Processing pipelines) were not easily handled. Long-term memory was a big problem in this sense, even with LSTM neural networks.
- Computationally intense training: the lack of parallelization in the training and the high number of required operation made the scaling of LSTMs or RNNs very difficult, so they couldn’t be implemented or shipped largely.
The transformers were able to solve these two issue, by employing several solutions that we will explore here, such as tokenization, vectorization, attention and normalization.
The transformer architecture
In this blog post, we will discuss the transformer architecture in a non-technical way, and we will refer to the one proposed by Vaswani et al. in their 2017 paper Attention is all you need.
Here you can find a visual representation, that we are going to break down in smaller pieces:
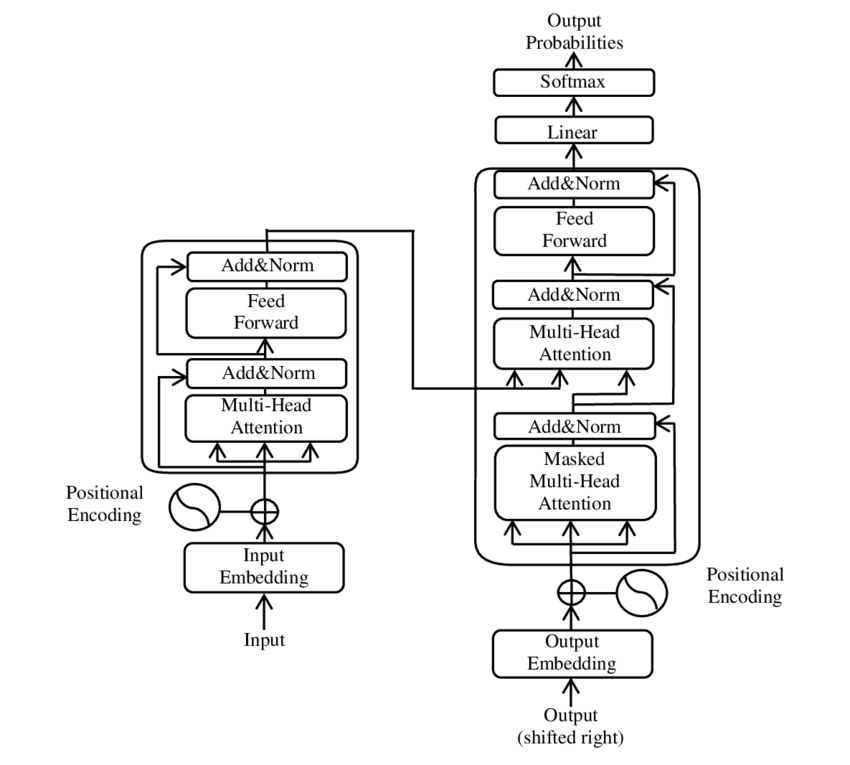
To understand everything, we’ll follow the path of the Italian sentence “Luca sta mangiando la torta” into our transformer, to translate it in English (“Luca is eating the cake”).
Encoder
The encoder is the first portion of the transformer: it turns natural language into a set of dense vectors of numeric values that can be handled by the decoder.
From input to input embedding
To feed our transformer with a sentence, we can’t pass over the natural language, as a computer doesn’t handle words like our brain does, it can only manage numbers. In this sense, we need to first tokenize and then vectorize our input, outputting what is called “embedding”.
The first step is then to subdivide our original sentence into batches, or tokens (let’s stick with a simple per-word batching: each word will represent a token): [“Luca”, “sta”, “mangiando”, “la”, “torta”].
From now on, we need to switch from letters to numbers, so let’s say we will embed these words as follows: [0.333, -1.456, 0.76, 0.89, 0.778] and turn them into the suitable vector or array-like object that our encorders takes as its real input.
Positional encoding and attention
As we can see, there is a precise order in the sentence: saying “Luca is eating the cake” is completely different from saying “The cake is eating Luca”. It is then key to encode not only the word per se, but also its position (this is particularly important in generative models for next-word/sentence prediction tasks). Generally, we do it by adding specific values to each word embedding, depending on its position.
In addition, we can see that there are internal relations among the words in the sentence (“is” is directly linked to “Luca” and not to “apple”, for example). How can we tell to the encoder that those words are connected to each other? Positional encoding itself is not enough, as it highlights an order, not a logic relation. Here it comes the key mechanism that sets transformers apart: attention.
In the attention process, each word (query) is compared to the others (values) using a set of keys that are defined for each sentence and that help the encoder in deciding what to focus on.
This works like a database querying system of a library: you search for some keywords that refer to the book you want to read, the query manager filters the request based on the keys according to which the database is organized and compares your search to a bunch of books that can be related to it, returning the most similar to your query. In this sense, the relation of each word with the other ones is evaluated and the higher the attentio output, the stronger is the relation between those words.
Feed forward neural network
Now that we have our “attentioned” word embeddings, we pass them through a feed forward neural network, which is generally a simple Multi-Layers Perceptron.
This helps extracting more feature from the embeddings, but there is no specific mechanism: each word embedding is processed following the same path.
Decoder
The decoder’s task is to turn word embeddings into probability scores that will be used by our model to:
- Predict the next word/sequence
- Translate a sentence
- Recognize and caption image portions
- Generate language or images
- And many other things…
The decoder, starting from the encoder inputs, goes through similar steps, adding another attention layer, a feed forward neural network and a final linear activation function with softmax normalization (which means that each value in the final output vector is turned into a probability score, and all the probability scores add up to 1).
Breakdown of decoder output
For our starting example, let’s say, we will have a matrix of probabilties that map the original words to their probable English translation. Let’s say that “sta” has a 77% probability of being “is” and a 23% probability of being “stays”: it will be then translated into “is”. “Torta” has a 98% probability of being “cake” and a 3% probability of being “pastry”, so it will be translated into “cake”. The same goes for every word, and the final output will be: “Luca is eating a cake”.
Decoder-only and encoder-only models
Decoder-only (GPT)
We described an encoder-decoder model, but the most famous of all Large Language Models, GPT, is based on a decoder-only architecture.
In the case of a decoder-only model, the word input is turned into embeddings directly by the decoder and, to supply for the absence of an encpder, the first attention step is to “mask” words in the sentence when paying attention: some words are purposedly ignored in calculating attention, in order for the model to focus on relevant information rather then using all the available one. Other attention steps can follow, but the decoder will proceed as we already saw previously.
Encoder-only (BERT)
Another really famous model is BERT (Bidirectional Encoder Representations for Transformers): it is encoder-only, and its purpose is not to generate text (for which it would need the probability scores that come out of a decoder), but is to understand relations among words and texts (it is used for sequence, token and text classification, for example).
Conclusion
In this post, we’ve embarked on a journey to demystify the concept of transformers, a revolutionary technique in the field of Natural Language Processing. We’ve broken down the transformer architecture into its constituent parts, exploring the encoder and decoder components, and delved into the key mechanisms that make transformers tick, such as tokenization, vectorization, attention, and normalization.
By understanding how transformers work, we can appreciate the power and flexibility of models like GPT and BERT, which have achieved state-of-the-art results in a wide range of NLP tasks. Whether you’re a seasoned developer or just starting to explore the world of AI, the concepts and techniques discussed in this post will provide a solid foundation for further learning and exploration.
So, the next time you hear someone mention “transformers” or “GPT,” you’ll know that it’s not just a buzzword - it’s a powerful technology that’s changing the face of AI and NLP.
References
For a deeper dive into the transformer architecture, I recommend checking out the following resources:
- Prashant Ram’s article on Medium, “Understanding the Transformer Architecture in AI Models” [1], which provides a concise introduction to the transformer architecture.
- The Wikipedia article on the Transformer (deep learning architecture) [2], which offers a comprehensive overview of the transformer model.
- Built In’s article on “Transformer Neural Network” [3], which provides a detailed yet brief explanation of the transformer.
- Towards Data Science’s article on “How Transformers Work” [4], which explores the transformer architecture and its role in natural language processing.
- Jean Nyandwi’s post on “The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture” [5], which offers a detailed breakdown of the transformer architecture and its components.
These resources provide a wealth of information on the transformer architecture and its applications in AI and NLP.
[1] Prashant Ram on on Medium: “Understanding the Transformer Architecture in AI Models”. https://medium.com/@prashantramnyc/understanding-the-transformer-architecture-in-ai-models-e9f937e79df2
[2] Wikipedia: “Transformer (deep learning architecture)”. https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture)
[3] Utkarsh Ankit on Built In: “Transformer Neural Network”. https://builtin.com/artificial-intelligence/transformer-neural-network
[4] Giuliano Giancaglia on Towards Data Science: “How Transformers work”. https://towardsdatascience.com/transformers-141e32e69591
[5] Jean Nyandwi on AI research blog: “The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture”. https://deeprevision.github.io/posts/001-transformer/