
Vector databases explained
Understanding the problem
Let’s say you want to set up a book store with ten thousand books, and you have the necessity to classify them in order to make them easily and readily available to your customers.
What would you do? You could decide to order them based on their title, the name of their author or their genre, but all of these approaches come with limitations and can impoverish the customers’ experience.
The best way to catalogue your books would be to give them a unique set of indices, based on their features (title, author first and last name, theme…): each of the book would then be stored on the shelves labelled with its own, original identifier.
Whoever wanted to search the store would be able to do it quickly, simply by accessing progressively smaller subsets of the books catalogue, until they reach the book of interest: this is not based only on the title or only on the author, but on a combination of keys that we are able to extract from the (meta)data associated with the books.
The idea behind vector databases is the same: they can be used to represent complex data, with lots of features, based on a set of multi-dimensional numeric objects (vectors). In this sense, we can collapse the information (contained in long texts, images, videos or other data) into numbers, without actually losing most of it but, at the same time, easing the access to it.
How is the database created?
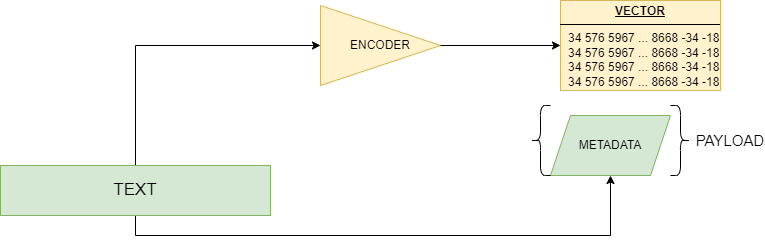
The first technical challenge we encounter with vector databases is transforming non numerical data into vectors, which are actually made up of numbers.
The extraction of features is generally achieved with an encoder: this is a checkpoint that can exploit several techniques, such as neural networks, traditional machine learning methods, hashing or other linear mapping procedures.
The encoder receives texts, images, videos or sounds, already variously preprocessed (e.g., subdivided in smaller batches), and is trained to recognized several patterns, structures and groups, compressing them into numeric representations that get piped into the vector.
The vectors can come along with metadata associated to the raw data: the whole object that is loaded to the vector database along with the vector is called “payload”.
It is not unusual that vector database providers employ quantization techniques, such as binary quantization, to speed up and lighten the memorization process: quantization is further compression of the information associated with data, rescaling it according to some rules. For example, the previously mentioned binary quantization works as follows: everything below a certain threshold (let’s say 0, for the sake of simplicity) is mapped to 0, everything above is mapped to 1; in this sense, a vector like: [0.34, -0.2, -0.98, 0.87, 0.03, -0.01] becomes: [1, 0, 0, 1, 1, 0].
In general, after having been encoded, loaded and (optionally) quantized, vectors are indexed, which means their similarity to already-existent vectors is computed and they are arranged into “semantic groups”: going back to our book store example, this is the same as putting on the same shelf all the fantasy books whose title starts with “A” and whose author’s first name is “Paul”.
The similarity can be computed with several techniques, such as:
- L2 (Euclidean) distance: takes into account the linear distance of two points on a plain
- L1 (Manhattan) distance: accounts for the sum of the projections on the axes of the line segments between two points on a plain
- Cosine: represents the cosine of the angle between two vectors on a plain
- Dot product: it’s the product of the module of two vectors, multiplied by the cosine of the angle between them
- Hamming distance: counts how many changes would it take to one vector to become like the other.
Now we have our data nicely vectorized and arranged into smaller, semantically similar subsets: time to use this database!
How is the database searched?
The database is generally searched with similarity-based techniques, which compute the degree of identity between two vectors (or among more) and retrieve the most similar N vectors (with N specified to the search algorithm).
The idea behind that is very simple abd can be visualized as follows:
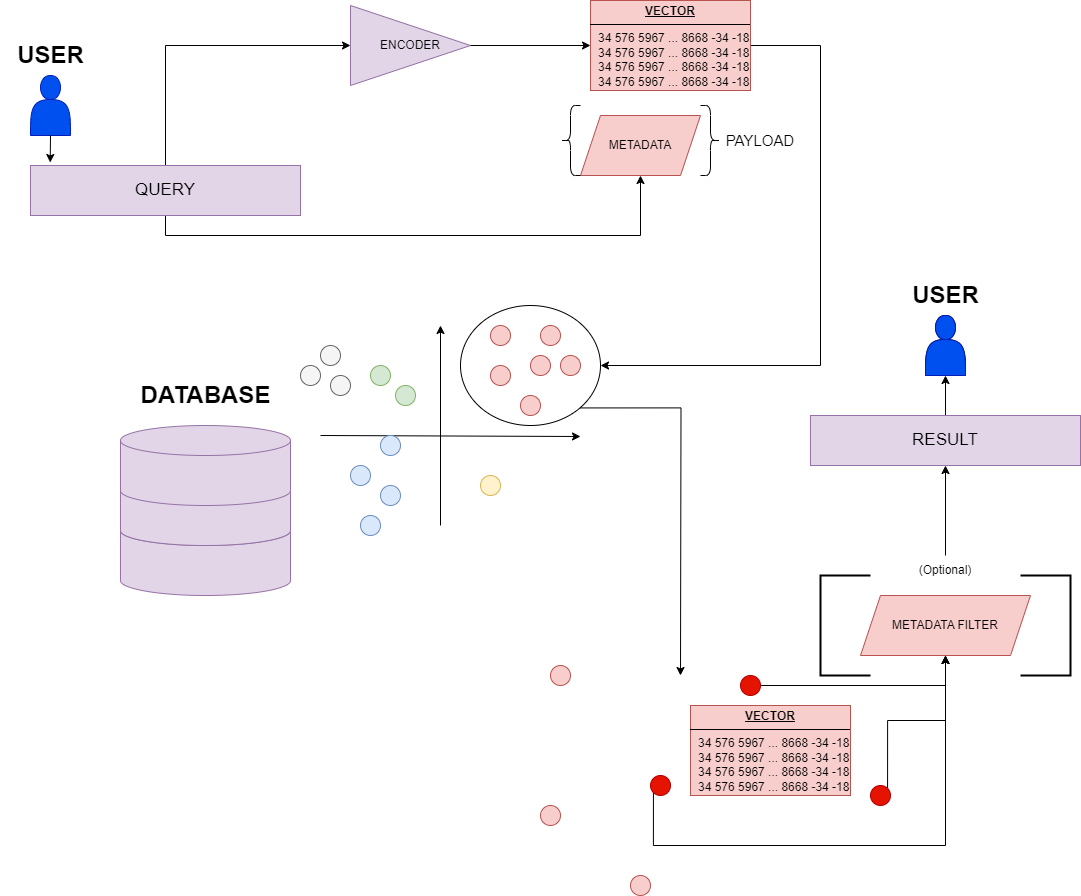
The query from the user gets transformed into a vector by an encoder, and is then compared to the already indexed database (the points on the xy plain are subdivided according to colors and positions): instead of comparing with all vectors and finding the most similar one, our query vector is readily paired with its most similar semantic group and then the N best-fitting data points are sorted and (optionally) filtered according to a pre-defined metadata filter. The result of the search is then returned to the user.
Similarity search is tremendously different from traditional keyword-based search: as a matter of facts, similarity search relies on a semantic architecture, which involves that two words like “mean” (noun) and “average” are highly similar but “mean” (verb) and “mean” (noun) are not. If you search for “the definition of ‘mean’ and ‘median’” using a traditional key-based search, chances are that you get something like: “The meaning is the definition of a word”, which is completely irrelevant to your original query. On the other hand, a semantic search “understands” the context, and may retrieve something like: “Mean (statistics): The average value of a set of numbers, calculated by summing all the values and dividing by the number of values”.
What are the most important use cases?
The most important use cases can be:
- RAG (Retrieval Augmented Generation): this is a technique employed to get more reliable responses from LLMs. It is not unusual that language models hallucinate, providing false or misleading information: you can build a vector database with all the relevant information you want your model to know and query the database right before feeding your request to the LLM, providing the results from your vector search as a context… This will remarkably improve the quality of the AI-generated answers!
- Image search and match, that can be useful to identify people, places, molecular structures, tumoral masses…
- Efficient storing and search among video and audio files: you could simply give a fragment of a song and get the highest-score matches back from the search results.
Conclusion
In a word where data throughput is skyrocketing, organizing them in an ordered, easy-to-access and fast retrieval friendly way will become a critical task in the near future.
Vector databases will probably prove as the best match to tackle the challenges of the huge load of data we will have to manage, so learning how they work and what services you can rely on to store and access your data is fundamental.
Here is a list of interesting vector database services (with the descriptions they provide of themselves):
- Qdrant: “Powering the next generation of AI applications with advanced and high-performant vector similarity search technology”
- ChromaDB: “Chroma is the open-source embedding database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs.”
- Pinecone: “The vector database to build knowledgeable AI”
- Weavite: “Weaviate is an open source, AI-native vector database that helps developers create intuitive and reliable AI-powered applications.”
There are, of course, many other providers, so do not stop exploring the world out there for new and better solutions!
References
- Leonie Monigatti, A Gentle Introduction To Vector Databases, 2023, https://weaviate.io/blog/what-is-a-vector-database#vector-search
- Wikipedia, Vector database, https://en.wikipedia.org/wiki/Vector_database
- Microsoft Learn, What is a vector database?, 2024, https://learn.microsoft.com/en-us/semantic-kernel/memories/vector-db
- Sabrina Aquino, What is a Vector Database?, 2024, https://qdrant.tech/articles/what-is-a-vector-database/
- Pavan Belgatti, Vector Databases: A Beginner’s Guide!, 2023, https://medium.com/data-and-beyond/vector-databases-a-beginners-guide-b050cbbe9ca0